
Complexity vs. scale in data projects
Differences and similarities

I watched the session by Alejandro Saucedo and Olaf Melchior from Zalando on building a data platform at Databricks' recent Data and AI Summit:
Their super interesting diagram on their data journey inspired me to consider the difference between ML/AI projects and more infrastructural ones as they scale. At Zalando, they decided to reimagine the whole infrastructure because complexity became a bottleneck to scaling. So, they adopted a more modern approach (moving to the cloud, microservices, distributed mesh, etc.). Then, they could scale without adding more complexity.
I interpret two things out of this:
Negative incentives often push developments in data engineering/infrastructure work, such as black box systems, complexity in code, inadequate performance, and price.
Once the transition to a modern platform is achieved, scale is easy(er).
I extended their diagram a bit:
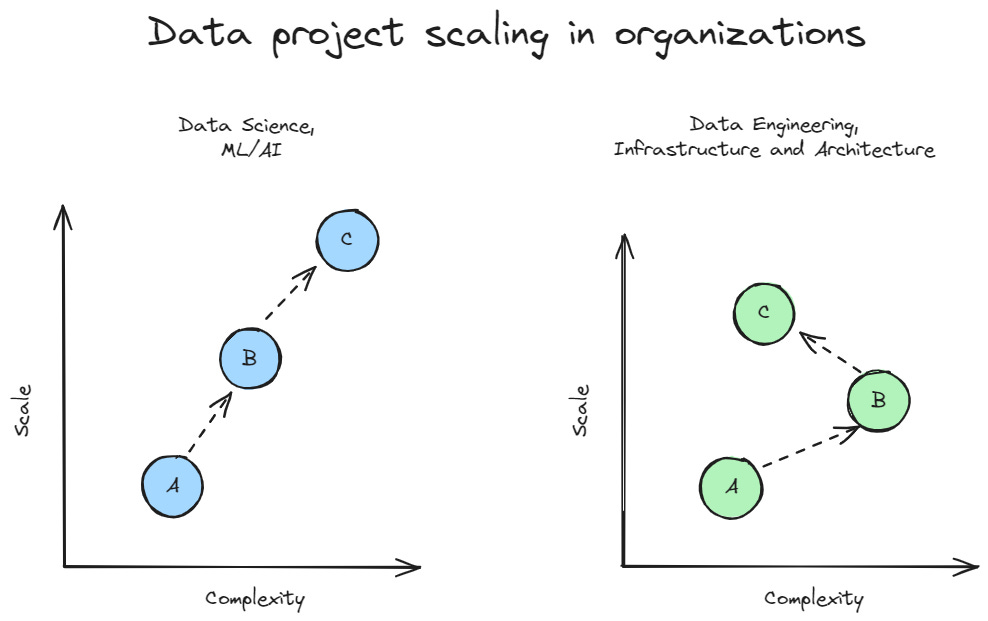
I wanted to contrast that with what I have seen in ML/AI projects. While the motivating factors are positive (get more value, automate a process, etc.), projects' complexity rises linearly with scale since new problems continuously emerge (such as edge cases and model drift).