
Generative AI really is different
Comparative ease of deployment can make all the difference for large organizations

First - hello after my summer break. I had a wonderful time recharging and refocusing; I hope you did so as well.
Now, I want to share my recent thoughts regarding generative AI. In conversations with larger organizations and leaders, I realized - how will we deploy advanced models before even mastering the basics? After all, widespread deployment of models in production is still rare in the enterprise. But it started drawing on me: generative AI will follow a different path and be much shorter than other ML/AI use cases. Here’s why:
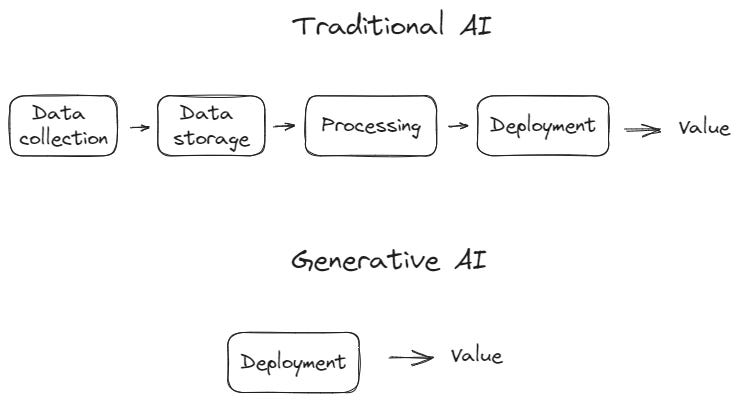
Traditional models require so much from an organization, both in terms of technology and resources. A complete data architecture would require data collection, storage, and processing. And you’ll need the people to build this for you.
As for generative AI, the data is often already collected and stored. Consider the huge amounts of internal documents, Confluence and SharePoint pages, and other unstructured data readily available in enterprise systems. These data barely need to be processed before being fed to a model - and even that is abstracted away - all you need is to call an Azure or OpenAI endpoint and display the results1.
This leads me to believe that organizations will be much faster in deploying such solutions than traditional models. And as I often say on this topic, there’s a huge first mover’s advantage at play.
I know I’m oversimplifying both cases to make the contrasting point; you need more preparation for generative AI, and the tools for traditional models are also mature - but still, there’s a huge difference in effort and resources between both.
Do you think the ease of deployment of generative AI will lead to a wider adoption of non-generative AI?