
Invest in enabling data projects (while you can)
Don't miss the forest for the trees

It’s an early January morning in Berlin, and I want to share a thought brewing in my head for the last several months. In October, I was at an event in Frankfurt focused on data leaders across the DACH region. It was a fantastic event, but one thing stood out to me - nobody talked about genAI, and there were almost no CDOs in the audience. In my talk, I joked that those two might be connected: because of the raised expectations and hype, many in that position struggle to have a lasting, measurable impact.
But is there more to it? I realized that many in the industry are heading for disaster unless we start seeing the fundamentals. What use are those use cases (excuse the pun) if they are not “enabled”? Let me phrase it as my main prediction for 2024 in data and AI:
After a significant push in creating many new pilot projects, especially in genAI, only the organizations that invest solidly in data-enabling technologies will reap benefits, while the rest will stumble and fail.
Many organizations find themselves at this stage. You have designed a valuable use case, built a prototype quickly, and now realize that edge cases and integration are a major issue - back to the drawing board. This is even more common with genAI because of the outsourcing of many components, such as model training to vendors, hiding the complexity1. Now, you need data architects, engineers, and an understanding of your legacy architecture. This mismatch between expectations and complexity can lead to disappointment and missed deadlines.
While I am a huge proponent of iterative, rapid prototyping approaches to data and AI-powered products (quickly proving value before you commit) - we should never ignore investments in enabling data projects. Otherwise, we can end up with no foundation2. Let’s visualize:
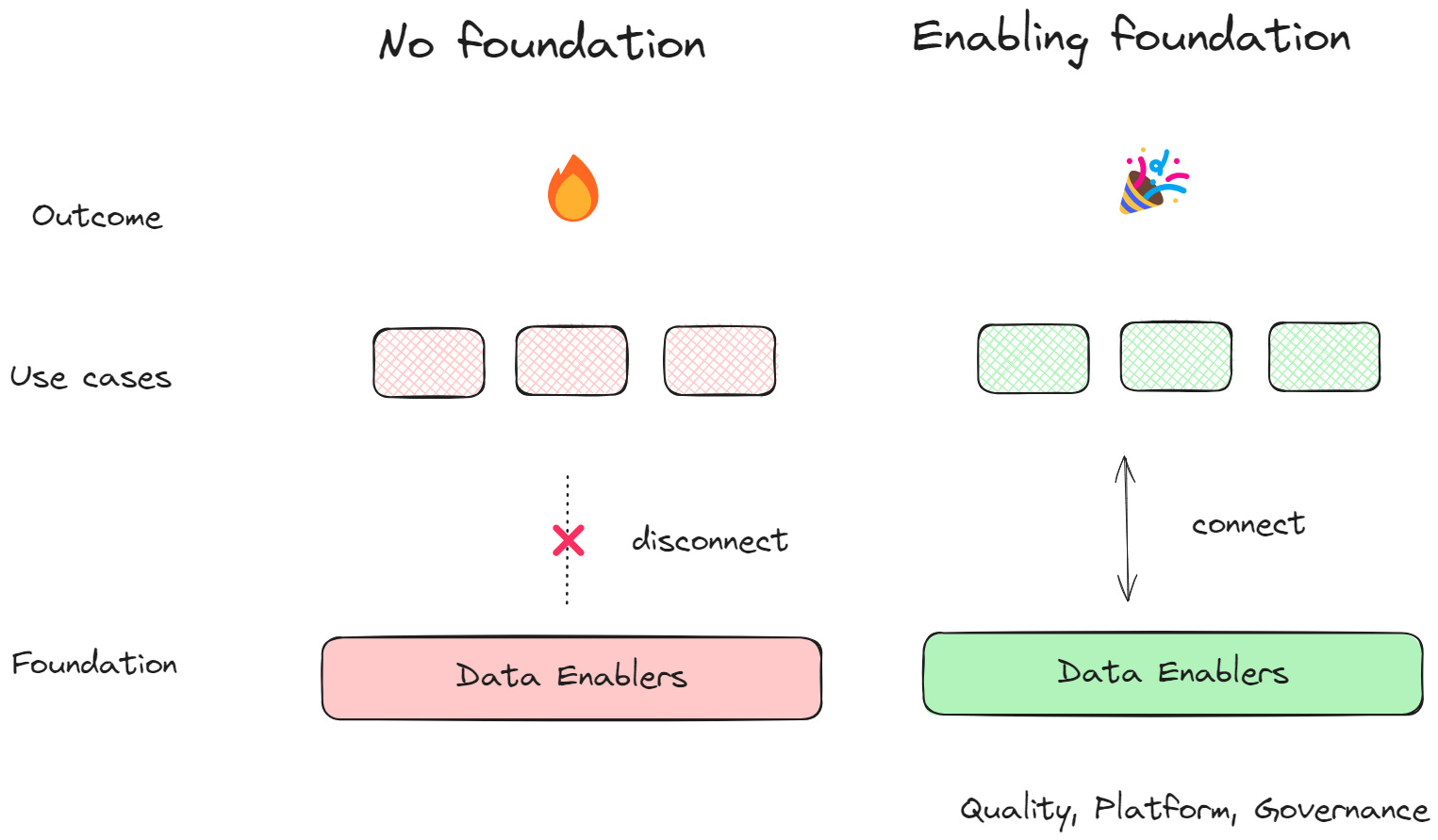
What are those data enablers? In this article, I want to focus on the technical ones; I’ll cover the others (such as culture and product thinking) in the future. Here are my top three, in no order:
Data quality. It all starts here, doesn’t it: run initiatives to check the most important datasets, build automation for checks in data pipelines, and invest in a data catalog.
Data platform. Use the power of the hyperscalers to your advantage: create sandbox environments for your data scientists, automate deployments with infrastructure as code, and ensure your product scaling and performance requirements are fulfilled.
Data governance. Balance widespread access with security and compliance by designing robust governance policies, building data products, and using frameworks such as data mesh (if this fits your organization).
At this point, even if you agree with me, you might ask yourself - it sounds great, but how do I manage this foundational work in a real environment? If it’s this important, it should be done before working on use cases, right? Of course, we can’t ignore the constraints in which we work - six months of work exclusively on enabling (often invisible) activities can be a hard sell to management, even if they have moderate expectations. Thus, we must apply a portfolio management approach and balance the work:
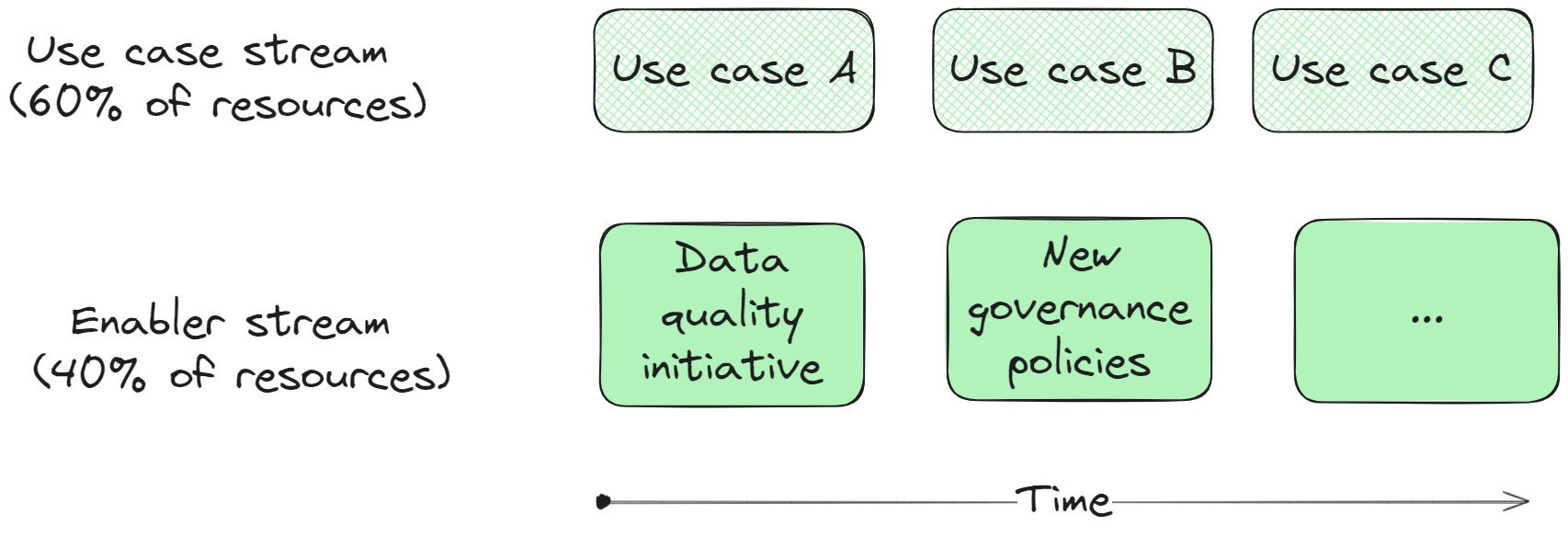
A two-stream approach is often viable, even advised - after all, how would we know which data platform functionalities to prioritize if we are not also working on the use cases that need the support? The ratio of resources depends on your case, if you are a larger organization you might get away with a larger chunk in the enabler stream.
To summarize: the best time to invest in those technologies was yesterday, but the second-best time is now.
I covered this particular difference between genAI and traditional AI architecture in a previous article.
This is an even bigger issue for traditional organizations on a legacy stack who are not far enough in their digital transformation journey.